Python Pandas DataFrame: Exercises, Practice, Solution
[An editor is available at the bottom of the page to write and execute the scripts.]
Pandas DataFrame [81 exercises with solution]

1. Write a Pandas program to get the powers of an array values element-wise. Go to the editor
Note: First array elements raised to powers from second array
Sample data: {'X':[78,85,96,80,86], 'Y':[84,94,89,83,86],'Z':[86,97,96,72,83]}
Expected Output:
X Y Z
0 78 84 86
1 85 94 97
2 96 89 96
3 80 83 72
4 86 86 83
Click me to see the sample solution
2. Write a Pandas program to create and display a DataFrame from a specified dictionary data which has the index labels. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
attempts name qualify score
a 1 Anastasia yes 12.5
b 3 Dima no 9.0
....
i 2 Kevin no 8.0
j 1 Jonas yes 19.0
Click me to see the sample solution
3. Write a Pandas program to display a summary of the basic information about a specified DataFrame and its data. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Summary of the basic information about this DataFrame and its data:
<class 'pandas.core.frame.DataFrame'>
Index: 10 entries, a to j
Data columns (total 4 columns):
....
dtypes: float64(1), int64(1), object(2)
memory usage: 400.0+ bytes
None
Click me to see the sample solution
4. Write a Pandas program to get the first 3 rows of a given DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
First three rows of the data frame:
attempts name qualify score
a 1 Anastasia yes 12.5
b 3 Dima no 9.0
c 2 Katherine yes 16.5
Click me to see the sample solution
5. Write a Pandas program to select the 'name' and 'score' columns from the following DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Select specific columns:
name score
a Anastasia 12.5
b Dima 9.0
c Katherine 16.5
...
h Laura NaN
i Kevin 8.0
j Jonas 19.0
Click me to see the sample solution
6. Write a Pandas program to select the specified columns and rows from a given data frame. Go to the editor
Sample Python dictionary data and list labels:
Select 'name' and 'score' columns in rows 1, 3, 5, 6 from the following data frame.
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Select specific columns and rows:
score qualify
b 9.0 no
d NaN no
f 20.0 yes
g 14.5 yes
Click me to see the sample solution
7. Write a Pandas program to select the rows where the number of attempts in the examination is greater than 2. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Number of attempts in the examination is greater than 2:
name score attempts qualify
b Dima 9.0 3 no
d James NaN 3 no
f Michael 20.0 3 yes
Click me to see the sample solution
8. Write a Pandas program to count the number of rows and columns of a DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Number of Rows: 10
Number of Columns: 4
Click me to see the sample solution
9. Write a Pandas program to select the rows where the score is missing, i.e. is NaN. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Rows where score is missing:
attempts name qualify score
d 3 James no NaN
h 1 Laura no NaN
Click me to see the sample solution
10. Write a Pandas program to select the rows the score is between 15 and 20 (inclusive). Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Rows where score between 15 and 20 (inclusive):
attempts name qualify score
c 2 Katherine yes 16.5
f 3 Michael yes 20.0
j 1 Jonas yes 19.0
Click me to see the sample solution
11. Write a Pandas program to select the rows where number of attempts in the examination is less than 2 and score greater than 15. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Number of attempts in the examination is less than 2 and score greater than 15 :
name score attempts qualify
j Jonas 19.0 1 yes
Click me to see the sample solution
12. Write a Pandas program to change the score in row 'd' to 11.5. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Change the score in row 'd' to 11.5:
attempts name qualify score
a 1 Anastasia yes 12.5
b 3 Dima no 9.0
c 2 Katherine yes 16.5
...
i 2 Kevin no 8.0
j 1 Jonas yes 19.0
Click me to see the sample solution
13. Write a Pandas program to calculate the sum of the examination attempts by the students. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Sum of the examination attempts by the students:
19
Click me to see the sample solution
14. Write a Pandas program to calculate the mean score for each different student in DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Mean score for each different student in data frame:
13.5625
Click me to see the sample solution
15. Write a Pandas program to append a new row 'k' to data frame with given values for each column. Now delete the new row and return the original DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Values for each column will be:
name : "Suresh", score: 15.5, attempts: 1, qualify: "yes", label: "k"
Expected Output:
Append a new row:
Print all records after insert a new record:
attempts name qualify score
a 1 Anastasia yes 12.5
b 3 Dima no 9.0
......
j 1 Jonas yes 19.0
k 1 Suresh yes 15.5
Delete the new row and display the original rows:
attempts name qualify score
a 1 Anastasia yes 12.5
b 3 Dima no 9.0
........
i 2 Kevin no 8.0
j 1 Jonas yes 19.0
Click me to see the sample solution
16. Write a Pandas program to sort the DataFrame first by 'name' in descending order, then by 'score' in ascending order. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Values for each column will be:
name : "Suresh", score: 15.5, attempts: 1, qualify: "yes", label: "k"
Expected Output:
Orginal rows:
name score attempts qualify
a Anastasia 12.5 1 yes
b Dima 9.0 3 no
c Katherine 16.5 2 yes
d James NaN 3 no
e Emily 9.0 2 no
f Michael 20.0 3 yes
g Matthew 14.5 1 yes
h Laura NaN 1 no
i Kevin 8.0 2 no
j Jonas 19.0 1 yes
Sort the data frame first by 'name' in descending order, then by 'score' in ascending order:
name score attempts qualify
a Anastasia 12.5 1 yes
b Dima 9.0 3 no
c Katherine 16.5 2 yes
d James NaN 3 no
e Emily 9.0 2 no
f Michael 20.0 3 yes
g Matthew 14.5 1 yes
h Laura NaN 1 no
i Kevin 8.0 2 no
j Jonas 19.0 1 yes
Click me to see the sample solution
17. Write a Pandas program to replace the 'qualify' column contains the values 'yes' and 'no' with True and False. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Replace the 'qualify' column contains the values 'yes' and 'no' with T
rue and False:
attempts name qualify score
a 1 Anastasia True 12.5
b 3 Dima False 9.0
......
i 2 Kevin False 8.0
j 1 Jonas True 19.0
Click me to see the sample solution
18. Write a Pandas program to change the name 'James' to 'Suresh' in name column of the DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Change the name 'James' to \?Suresh\?:
attempts name qualify score
a 1 Anastasia yes 12.5
b 3 Dima no 9.0
.......
i 2 Kevin no 8.0
j 1 Jonas yes 19.0
Click me to see the sample solution
19. Write a Pandas program to delete the 'attempts' column from the DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
Delete the 'attempts' column from the data frame:
name qualify score
a Anastasia yes 12.5
b Dima no 9.0
.....
i Kevin no 8.0
j Jonas yes 19.0
Click me to see the sample solution
20. Write a Pandas program to insert a new column in existing DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
New DataFrame after inserting the 'color' column
attempts name qualify score color
a 1 Anastasia yes 12.5 Red
b 3 Dima no 9.0 Blue
.......
i 2 Kevin no 8.0 Green
j 1 Jonas yes 19.0 Red
Click me to see the sample solution
21. Write a Pandas program to iterate over rows in a DataFrame. Go to the editor
Sample Python dictionary data and list labels:
exam_data = [{'name':'Anastasia', 'score':12.5}, {'name':'Dima','score':9}, {'name':'Katherine','score':16.5}]
Expected Output:
Anastasia 12.5
Dima 9.0
Katherine 16.5
Click me to see the sample solution
22. Write a Pandas program to get list from DataFrame column headers. Go to the editor
Sample Python dictionary data and list labels:
exam_data = {'name': ['Anastasia', 'Dima', 'Katherine', 'James', 'Emily', 'Michael', 'Matthew', 'Laura', 'Kevin', 'Jonas'],
'score': [12.5, 9, 16.5, np.nan, 9, 20, 14.5, np.nan, 8, 19],
'attempts': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'qualify': ['yes', 'no', 'yes', 'no', 'no', 'yes', 'yes', 'no', 'no', 'yes']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Expected Output:
['attempts', 'name', 'qualify', 'score']
Click me to see the sample solution
23. Write a Pandas program to rename columns of a given DataFrame Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 9
New DataFrame after renaming columns:
Column1 Column2 Column3
0 1 4 7
1 2 5 8
2 3 6 9
Click me to see the sample solution
24. Write a Pandas program to select rows from a given DataFrame based on values in some columns. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
Rows for colum1 value == 4
col1 col2 col3
1 4 5 8
3 4 7 0
Click me to see the sample solution
25. Write a Pandas program to change the order of a DataFrame columns. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
After altering col1 and col3
col3 col2 col1
0 7 4 1
1 8 5 4
2 9 6 3
3 0 7 4
4 1 8 5
Click me to see the sample solution
26. Write a Pandas program to add one row in an existing DataFrame. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
After add one row:
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
5 10 11 12
Click me to see the sample solution
27. Write a Pandas program to write a DataFrame to CSV file using tab separator. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
Data from new_file.csv file:
col1\tcol2\tcol3
0 1\t4\t7
1 4\t5\t8
2 3\t6\t9
3 4\t7\t0
4 5\t8\t1
Click me to see the sample solution
28. Write a Pandas program to count city wise number of people from a given of data set (city, name of the person). Go to the editor
Sample data:
city Number of people
0 California 4
1 Georgia 2
2 Los Angeles 4
Click me to see the sample solution
29. Write a Pandas program to delete DataFrame row(s) based on given column value. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
New DataFrame
col1 col2 col3
0 1 4 7
2 3 6 9
3 4 7 0
4 5 8 1
Click me to see the sample solution
30. Write a Pandas program to widen output display to see more columns. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
Click me to see the sample solution
31. Write a Pandas program to select a row of series/dataframe by given integer index. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
Index-2: Details
col1 col2 col3
2 3 6 9
Click me to see the sample solution
32. Write a Pandas program to replace all the NaN values with Zero's in a column of a dataframe. Go to the editor
Sample data:
Original DataFrame
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
New DataFrame replacing all NaN with 0:
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no 0.0
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no 0.0
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
Click me to see the sample solution
33. Write a Pandas program to convert index in a column of the given dataframe. Go to the editor
Sample data:
Original DataFrame
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
After converting index in a column:
index attempts name qualify score
0 0 1 Anastasia yes 12.5
1 1 3 Dima no 9.0
2 2 2 Katherine yes 16.5
3 3 3 James no NaN
4 4 2 Emily no 9.0
5 5 3 Michael yes 20.0
6 6 1 Matthew yes 14.5
7 7 1 Laura no NaN
8 8 2 Kevin no 8.0
9 9 1 Jonas yes 19.0
Hiding index:
index attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
Click me to see the sample solution
34. Write a Pandas program to set a given value for particular cell in DataFrame using index value. Go to the editor
Sample data:
Original DataFrame
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
Set a given value for particular cell in the DataFrame
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 10.2
9 1 Jonas yes 19.0
Click me to see the sample solution
35. Write a Pandas program to count the NaN values in one or more columns in DataFrame. Go to the editor
Sample data:
Original DataFrame
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
Number of NaN values in one or more columns:
2
Click me to see the sample solution
36. Write a Pandas program to drop a list of rows from a specified DataFrame. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 4 5 8
2 3 6 9
3 4 7 0
4 5 8 1
New DataFrame after removing 2nd & 4th rows:
col1 col2 col3
0 1 4 7
1 4 5 8
3 4 7 0
Click me to see the sample solution
37. Write a Pandas program to reset index in a given DataFrame. Go to the editor
Sample data:
Original DataFrame
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
After removing first and second rows
attempts name qualify score
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
Reset the Index:
index attempts name qualify score
0 2 2 Katherine yes 16.5
1 3 3 James no NaN
2 4 2 Emily no 9.0
3 5 3 Michael yes 20.0
4 6 1 Matthew yes 14.5
5 7 1 Laura no NaN
6 8 2 Kevin no 8.0
7 9 1 Jonas yes 19.0
Click me to see the sample solution
38. Write a Pandas program to divide a DataFrame in a given ratio.Go to the editor
Sample data:
Original DataFrame:
0 1
0 0.316147 -0.767359
1 -0.813410 -2.522672
2 0.869615 1.194704
3 -0.892915 -0.055133
4 -0.341126 0.518266
5 1.857342 1.361229
6 -0.044353 -1.205002
7 -0.726346 -0.535147
8 -1.350726 0.563117
9 1.051666 -0.441533
70% of the said DataFrame:
0 1
8 -1.350726 0.563117
2 0.869615 1.194704
5 1.857342 1.361229
6 -0.044353 -1.205002
3 -0.892915 -0.055133
1 -0.813410 -2.522672
0 0.316147 -0.767359
30% of the said DataFrame:
0 1
4 -0.341126 0.518266
7 -0.726346 -0.535147
9 1.051666 -0.441533
Click me to see the sample solution
39. Write a Pandas program to combining two series into a DataFrame. Go to the editor
Sample data:
Data Series:
0 100
1 200
2 python
3 300.12
4 400
dtype: object
0 10
1 20
2 php
3 30.12
4 40
dtype: object
New DataFrame combining two series:
0 1
0 100 10
1 200 20
2 python php
3 300.12 30.12
4 400 40
Click me to see the sample solution
40. Write a Pandas program to shuffle a given DataFrame rows. Go to the editor
Sample data:
Original DataFrame:
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
2 2 Katherine yes 16.5
3 3 James no NaN
4 2 Emily no 9.0
5 3 Michael yes 20.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
New DataFrame:
attempts name qualify score
5 3 Michael yes 20.0
0 1 Anastasia yes 12.5
9 1 Jonas yes 19.0
6 1 Matthew yes 14.5
7 1 Laura no NaN
1 3 Dima no 9.0
3 3 James no NaN
4 2 Emily no 9.0
8 2 Kevin no 8.0
2 2 Katherine yes 16.5
Click me to see the sample solution
41. Write a Pandas program to convert DataFrame column type from string to datetime.
Go to the editor
Sample data:
String Date:
0 3/11/2000
1 3/12/2000
2 3/13/2000
dtype: object
Original DataFrame (string to datetime):
0
0 2000-03-11
1 2000-03-12
2 2000-03-13
Click me to see the sample solution
42. Write a Pandas program to rename a specific column name in a given DataFrame. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 9
New DataFrame after renaming second column:
col1 Column2 col3
0 1 4 7
1 2 5 8
2 3 6 9
Click me to see the sample solution
43. Write a Pandas program to get a list of a specified column of a DataFrame. Go to the editor
Sample data:
Powered by
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 9
Col2 of the DataFrame to list:
[4, 5, 6]
Click me to see the sample solution
44. Write a Pandas program to create a DataFrame from a Numpy array and specify the index column and column headers. Go to the editor
Sample Output:
Column1 Column2 Column3
Index1 0 0.0 0.0
Index2 0 0.0 0.0
Index3 0 0.0 0.0
.........
Index12 0 0.0 0.0
Index13 0 0.0 0.0
Index14 0 0.0 0.0
Index15 0 0.0 0.0
Click me to see the sample solution
45. Write a Pandas program to find the row for where the value of a given column is maximum. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 12
3 4 9 1
4 7 5 11
Row where col1 has maximum value:
4
Row where col2 has maximum value:
3
Row where col3 has maximum value:
2
Click me to see the sample solution
46. Write a Pandas program to check whether a given column is present in a DataFrame or not. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 12
3 4 9 1
4 7 5 11
Col4 is not present in DataFrame.
Col1 is present in DataFrame.
Click me to see the sample solution
47. Write a Pandas program to get the specified row value of a given DataFrame. Go to the editor
Sample data:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 12
3 4 9 1
4 7 5 11
Value of Row
col1 1
col2 4
col3 7
Name: 0, dtype: int64
Value of Row4
col1 4
col2 9
col3 1
Name: 3, dtype: int64
Click me to see the sample solution
48. Write a Pandas program to get the datatypes of columns of a DataFrame. Go to the editor
Sample data:
Original DataFrame:
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
.......
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
Data types of the columns of the said DataFrame:
attempts int64
name object
qualify object
score float64
dtype: object
Click me to see the sample solution
49. Write a Pandas program to append data to an empty DataFrame. Go to the editor
Sample data:
Original DataFrame:
After appending some data:
col1 col2
0 0 0
1 1 1
2 2 2
Click me to see the sample solution
50. Write a Pandas program to sort a given DataFrame by two or more columns. Go to the editor
Sample data:
Original DataFrame:
attempts name qualify score
0 1 Anastasia yes 12.5
1 3 Dima no 9.0
........
8 2 Kevin no 8.0
9 1 Jonas yes 19.0
Sort the above DataFrame on attempts, name:
attempts name qualify score
0 1 Anastasia yes 12.5
9 1 Jonas yes 19.0
7 1 Laura no NaN
6 1 Matthew yes 14.5
4 2 Emily no 9.0
2 2 Katherine yes 16.5
8 2 Kevin no 8.0
1 3 Dima no 9.0
3 3 James no NaN
5 3 Michael yes 20.0
Click me to see the sample solution
51. Write a Pandas program to convert the datatype of a given column (floats to ints). Go to the editor
Sample data:
Original DataFrame:
attempts name qualify score
0 1 Anastasia yes 12.50
1 3 Dima no 9.10
......
8 2 Kevin no 8.80
9 1 Jonas yes 19.13
Data types of the columns of the said DataFrame:
attempts int64
name object
qualify object
score float64
dtype: object
Now change the Data type of 'score' column from float to int:
attempts name qualify score
0 1 Anastasia yes 12
1 3 Dima no 9
2 2 Katherine yes 16
3 3 James no 12
4 2 Emily no 9
5 3 Michael yes 20
6 1 Matthew yes 14
7 1 Laura no 11
8 2 Kevin no 8
9 1 Jonas yes 19
Data types of the columns of the DataFrame now:
attempts int64
name object
qualify object
score int64
dtype: object
Click me to see the sample solution
52. Write a Pandas program to remove infinite values from a given DataFrame. Go to the editor
Sample data:
Original DataFrame:
0
0 1000.000000
1 2000.000000
2 3000.000000
3 -4000.000000
4 inf
5 -inf
Removing infinite values:
0
0 1000.0
1 2000.0
2 3000.0
3 -4000.0
4 NaN
5 NaN
Click me to see the sample solution
53. Write a Pandas program to insert a given column at a specific column index in a DataFrame. Go to the editor
Sample data:
Original DataFrame
col2 col3
0 4 7
1 5 8
2 6 12
3 9 1
4 5 11
New DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 12
3 4 9 1
4 7 5 11
Click me to see the sample solution
54. Write a Pandas program to convert a given list of lists into a Dataframe. Go to the editor
Sample data:
Original list of lists:
[[2, 4], [1, 3]]
New DataFrame
col1 col2
0 2 4
1 1 3
Click me to see the sample solution
55. Write a Pandas program to group by the first column and get second column as lists in rows. Go to the editor
Sample data:
Original DataFrame
col1 col2
0 C1 1
1 C1 2
2 C2 3
3 C2 3
4 C2 4
5 C3 6
6 C2 5
Group on the col1:
col1
C1 [1, 2]
C2 [3, 3, 4, 5]
C3 [6]
Name: col2, dtype: object
Click me to see the sample solution
56. Write a Pandas program to get column index from column name of a given DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 12
3 4 9 1
4 7 5 11
Index of 'col2'
1
Click me to see the sample solution
57. Write a Pandas program to count number of columns of a DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 12
3 4 9 1
4 7 5 11
Number of columns:
3
Click me to see the sample solution
58. Write a Pandas program to select all columns, except one given column in a DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 8
2 3 6 12
3 4 9 1
4 7 5 11
All columns except 'col3':
col1 col2
0 1 4
1 2 5
2 3 6
3 4 9
4 7 5
Click me to see the sample solution
59. Write a Pandas program to get first n records of a DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
3 4 9 12
4 7 5 1
5 11 0 11
First 3 rows of the said DataFrame':
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
Click me to see the sample solution
60. Write a Pandas program to get last n records of a DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
3 4 9 12
4 7 5 1
5 11 0 11
Last 3 rows of the said DataFrame':
col1 col2 col3
3 4 9 12
4 7 5 1
5 11 0 11
Click me to see the sample solution
61. Write a Pandas program to get topmost n records within each group of a DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
3 4 9 12
4 7 5 1
5 11 0 11
topmost n records within each group of a DataFrame:
col1 col2 col3
5 11 0 11
4 7 5 1
3 4 9 12
col1 col2 col3
3 4 9 12
2 3 6 8
1 2 5 5
4 7 5 1
col1 col2 col3
3 4 9 12
5 11 0 11
2 3 6 8
Click me to see the sample solution
62. Write a Pandas program to remove first n rows of a given DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
3 4 9 12
4 7 5 1
5 11 0 11
After removing first 3 rows of the said DataFrame:
col1 col2 col3
3 4 9 12
4 7 5 1
5 11 0 11
Click me to see the sample solution
63. Write a Pandas program to remove last n rows of a given DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
3 4 9 12
4 7 5 1
5 11 0 11
After removing last 3 rows of the said DataFrame:
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
Click me to see the sample solution
64. Write a Pandas program to add a prefix or suffix to all columns of a given DataFrame. Go to the editor
Sample Output:
Original DataFrame
W X Y Z
0 68 78 84 86
1 75 85 94 97
2 86 96 89 96
3 80 80 83 72
4 66 86 86 83
Add prefix:
A_W A_X A_Y A_Z
0 68 78 84 86
1 75 85 94 97
2 86 96 89 96
3 80 80 83 72
4 66 86 86 83
Add suffix:
W_1 X_1 Y_1 Z_1
0 68 78 84 86
1 75 85 94 97
2 86 96 89 96
3 80 80 83 72
4 66 86 86 83
Click me to see the sample solution
65. Write a Pandas program to reverse order (rows, columns) of a given DataFrame. Go to the editor
Sample Output:
Original DataFrame
W X Y Z
0 68 78 84 86
1 75 85 94 97
2 86 96 89 96
3 80 80 83 72
4 66 86 86 83
Reverse column order:
Z Y X W
0 86 84 78 68
1 97 94 85 75
2 96 89 96 86
3 72 83 80 80
4 83 86 86 66
Reverse row order:
W X Y Z
4 66 86 86 83
3 80 80 83 72
2 86 96 89 96
1 75 85 94 97
0 68 78 84 86
Reverse row order and reset index:
W X Y Z
0 66 86 86 83
1 80 80 83 72
2 86 96 89 96
3 75 85 94 97
4 68 78 84 86
Click me to see the sample solution
66. Write a Pandas program to select columns by data type of a given DataFrame. Go to the editor
Sample Output:
Original DataFrame
name date_of_birth age
0 Alberto Franco 17/05/2002 18.5
1 Gino Mcneill 16/02/1999 21.2
2 Ryan Parkes 25/09/1998 22.5
3 Eesha Hinton 11/05/2002 22.0
4 Syed Wharton 15/09/1997 23.0
Select numerical columns
age
0 18.5
1 21.2
2 22.5
3 22.0
4 23.0
Select string columns
name date_of_birth
0 Alberto Franco 17/05/2002
1 Gino Mcneill 16/02/1999
2 Ryan Parkes 25/09/1998
3 Eesha Hinton 11/05/2002
4 Syed Wharton 15/09/1997
Click me to see the sample solution
67. Write a Pandas program to split a given DataFrame into two random subsets. Go to the editor
Sample Output:
Original Dataframe and shape:
name date_of_birth age
0 Alberto Franco 17/05/2002 18
1 Gino Mcneill 16/02/1999 21
2 Ryan Parkes 25/09/1998 22
3 Eesha Hinton 11/05/2002 22
4 Syed Wharton 15/09/1997 23
(5, 3)
Subset-1 and shape:
name date_of_birth age
1 Gino Mcneill 16/02/1999 21
4 Syed Wharton 15/09/1997 23
2 Ryan Parkes 25/09/1998 22
(3, 3)
Subset-2 and shape:
name date_of_birth age
0 Alberto Franco 17/05/2002 18
3 Eesha Hinton 11/05/2002 22
(2, 3)
Click me to see the sample solution
68. Write a Pandas program to rename all columns with the same pattern of a given DataFrame. Go to the editor
Sample Output:
Original DataFrame
Name Date_Of_Birth Age
0 Alberto Franco 17/05/2002 18.5
1 Gino Mcneill 16/02/1999 21.2
2 Ryan Parkes 25/09/1998 22.5
3 Eesha Hinton 11/05/2002 22.0
4 Syed Wharton 15/09/1997 23.0
Remove trailing (at the end) whitesapce and convert to lowercase of the columns name
name date_of_birth age
0 Alberto Franco 17/05/2002 18.5
1 Gino Mcneill 16/02/1999 21.2
2 Ryan Parkes 25/09/1998 22.5
3 Eesha Hinton 11/05/2002 22.0
4 Syed Wharton 15/09/1997 23.0
Click me to see the sample solution
69. Write a Pandas program to merge datasets and check uniqueness. Go to the editor
Sample Output:
Original DataFrame:
Name Date_Of_Birth Age
0 Alberto Franco 17/05/2002 18.5
1 Gino Mcneill 16/02/1999 21.2
2 Ryan Parkes 25/09/1998 22.5
3 Eesha Hinton 11/05/2002 22.0
4 Syed Wharton 15/09/1997 23.0
New DataFrames:
Name Date_Of_Birth Age
2 Ryan Parkes 25/09/1998 22.5
3 Eesha Hinton 11/05/2002 22.0
4 Syed Wharton 15/09/1997 23.0
Name Date_Of_Birth Age
0 Alberto Franco 17/05/2002 18.5
1 Gino Mcneill 16/02/1999 21.2
3 Eesha Hinton 11/05/2002 22.0
4 Syed Wharton 15/09/1997 23.0
"one_to_one": check if merge keys are unique in both left and right datasets:"
Name Date_Of_Birth Age
0 Eesha Hinton 11/05/2002 22.0
1 Syed Wharton 15/09/1997 23.0
"one_to_many" or "1:m": check if merge keys are unique in left dataset:
Name Date_Of_Birth Age
0 Eesha Hinton 11/05/2002 22.0
1 Syed Wharton 15/09/1997 23.0
"any_to_one" or "m:1": check if merge keys are unique in right dataset:
Name Date_Of_Birth Age
0 Eesha Hinton 11/05/2002 22.0
1 Syed Wharton 15/09/1997 23.0
Click me to see the sample solution
70. Write a Pandas program to convert continuous values of a column in a given DataFrame to categorical. Go to the editor
Input:
{ 'Name': ['Alberto Franco','Gino Mcneill','Ryan Parkes', 'Eesha Hinton', 'Syed Wharton'],
'Age': [18, 22, 40, 50, 80, 5] }
Output:
Age group:
0 kids
1 adult
2 elderly
3 adult
4 elderly
5 kids
Name: age_groups, dtype: category
Categories (3, object): [kids < adult < elderly]
Click me to see the sample solution
71. Write a Pandas program to display memory usage of a given DataFrame and every column of the DataFrame. Go to the editor
Sample Output:
Original DataFrame:
Name Date_Of_Birth Age
0 Alberto Franco 17/05/2002 18.5
1 Gino Mcneill 16/02/1999 21.2
2 Ryan Parkes 25/09/1998 22.5
3 Eesha Hinton 11/05/2002 22.0
4 Syed Wharton 15/09/1997 23.0
Global usage of memory of the DataFrame:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 3 columns):
Name 5 non-null object
Date_Of_Birth 5 non-null object
Age 5 non-null float64
dtypes: float64(1), object(2)
memory usage: 801.0 bytes
None
The usage of memory of every column of the said DataFrame:
Index 80
Name 346
Date_Of_Birth 335
Age 40
dtype: int64
Click me to see the sample solution
72. Write a Pandas program to combine many given series to create a DataFrame. Go to the editor
Sample Output:
Original Series:
0 php
1 python
2 java
3 c#
4 c++
dtype: object
0 1
1 2
2 3
3 4
4 5
dtype: int64
Combine above series to a dataframe:
index 0
0 1 python
1 2 java
2 3 c#
3 4 c++
4 5 NaN
Using pandas concat:
0 1
0 php 1
1 python 2
2 java 3
3 c# 4
4 c++ 5
Using pandas DataFrame with a dictionary, gives a specific name to the columns:
col1 col2
0 php 1
1 python 2
2 java 3
3 c# 4
4 c++ 5
Click me to see the sample solution
73. Write a Pandas program to create DataFrames that contains random values, contains missing values, contains datetime values and contains mixed values. Go to the editor
Sample Output:
DataFrame: Contains random values:
A B C D
Dog2w4Dv4l 0.591058 1.883454 -1.608613 -0.502516
kV7mfdFcF9 0.629642 -0.474377 0.567357 1.658445
.......
DataFrame: Contains missing values:
A B C D
i6i6Xn9l9c -0.299335 0.410871 -0.431840 -0.302177
OGo5KNNYNJ -0.174594 -1.366146 0.435063 -2.779446
u0mG9q1L7C 1.019094 -0.061077 -1.138138 -0.218460
RNJGqpci4o -0.380815 0.189970 -2.148521 -1.163589
vXIcxItZ1D NaN -0.079448 0.604777 0.065290
........
DataFrame: Contains datetime values:
A B C D
2000-01-03 0.665402 0.860808 -0.180986 -0.970889
2000-01-04 -1.511533 0.487539 -0.710355 -0.807816
2000-01-05 -0.773294 0.197918 -1.214035 1.049529
2000-01-06 -1.074894 1.774147 -0.620025 0.740779
.......
DataFrame: Contains mixed values:
A B C D
0 0.0 0.0 foo1 2009-01-01
1 1.0 1.0 foo2 2009-01-02
2 2.0 0.0 foo3 2009-01-05
3 3.0 1.0 foo4 2009-01-06
4 4.0 0.0 foo5 2009-01-07
Click me to see the sample solution
74. Write a Pandas program to fill missing values in time series data. Go to the editor
From Wikipedia , in the mathematical field of numerical analysis, interpolation is a type of estimation, a method of constructing new data points within the range of a discrete set of known data points.
Sample Output:
Original DataFrame:
c1 c2
2000-01-03 120.0 7.0
2000-01-04 130.0 NaN
2000-01-05 140.0 10.0
2000-01-06 150.0 NaN
2000-01-07 NaN 5.5
2000-01-10 170.0 16.5
DataFrame after interpolate:
c1 c2
2000-01-03 120.0 7.00
2000-01-04 130.0 8.50
2000-01-05 140.0 10.00
2000-01-06 150.0 7.75
2000-01-07 160.0 5.50
2000-01-10 170.0 16.50
Click me to see the sample solution
75. Write a Pandas program to use a local variable within a query. Go to the editor
Sample Output:
Original DataFrame
W X Y Z
0 68 78 84 86
1 75 85 94 97
2 86 96 89 96
3 80 80 83 72
4 66 86 86 83
Values which are less than maximum value of 'W' column
W X Y Z
0 68 78 84 86
1 75 85 94 97
3 80 80 83 72
4 66 86 86 83
Click me to see the sample solution
76. Write a Pandas program to clean object column with mixed data of a given DataFrame using regular expression. Go to the editor
Sample Output:
Original dataframe:
agent purchase
0 a001 4500
1 a002 7500
2 a003 $3000.25
3 a003 $1250.35
4 a004 9000.00
Data Types:
0 <class 'float'>
1 <class 'float'>
2 <class 'str'>
3 <class 'str'>
4 <class 'str'>
Name: purchase, dtype: object
New Data Types:
0 <class 'float'>
1 <class 'float'>
2 <class 'float'>
3 <class 'float'>
4 <class 'float'>
Name: purchase, dtype: object
Click me to see the sample solution
77. Write a Pandas program to get the numeric representation of an array by identifying distinct values of a given column of a dataframe. Go to the editor
Sample Output:
Original DataFrame:
Name Date_Of_Birth Age
0 Alberto Franco 17/05/2002 18.5
1 Gino Mcneill 16/02/1999 21.2
2 Ryan Parkes 25/09/1998 22.5
3 Eesha Hinton 11/05/2002 22.0
4 Gino Mcneill 15/09/1997 23.0
Numeric representation of an array by identifying distinct values:
[0 1 2 3 1]
Index(['Alberto Franco', 'Gino Mcneill', 'Ryan Parkes', 'Eesha Hinton'], dtype='object')
Click me to see the sample solution
78. Write a Pandas program to replace the current value in a dataframe column based on last largest value. If the current value is less than last largest value replaces the value with 0. Go to the editor
Test data:
rnum
0 23
1 21
2 27
3 22
...
10 34
11 19
12 31
13 32
14 19
Sample Output:
Original DataFrame:
rnum
0 23
1 21
2 27
3 22
...
10 34
11 19
12 31
13 32
14 19
Replace current value in a dataframe column based on last largest value:
rnum
0 23
1 0
2 27
3 0
...
10 34
11 0
12 0
13 0
14 0
Click me to see the sample solution
79. Write a Pandas program to create a DataFrame from the clipboard (data from an Excel spreadsheet or a Google Sheet). Go to the editor
Sample Excel Data:
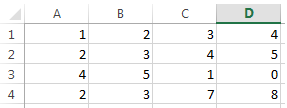
Sample Output:
Data from clipboard to DataFrame:
1 2 3 4
0 2 3 4 5
1 4 5 1 0
2 2 3 7 8
Click me to see the sample solution
80. Write a Pandas program to check for inequality of two given DataFrames. Go to the editor
Sample Output:
Original DataFrames:
W X Y Z
0 68.0 78.0 84 86
1 75.0 85.0 94 97
2 86.0 NaN 89 96
3 80.0 80.0 83 72
4 NaN 86.0 86 83
W X Y Z
0 78.0 78 84 86
1 75.0 85 84 97
2 86.0 96 89 96
3 80.0 80 83 72
4 NaN 76 86 83
Check for inequality of the said dataframes:
W X Y Z
0 True False False False
1 False False True False
2 False True False False
3 False False False False
4 True True False False
Click me to see the sample solution
81. Write a Pandas program to get lowest n records within each group of a given DataFrame. Go to the editor
Sample Output:
Original DataFrame
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
3 4 9 12
4 7 5 1
5 11 0 11
Lowest n records within each group of a DataFrame:
col1 col2 col3
0 1 4 7
1 2 5 5
2 3 6 8
col1 col2 col3
5 11 0 11
0 1 4 7
1 2 5 5
col1 col2 col3
4 7 5 1
1 2 5 5
0 1 4 7
Click me to see the sample solution
Python-Pandas Code Editor:
More to Come !
Do not submit any solution of the above exercises at here, if you want to contribute go to the appropriate exercise page.
Test your Python skills with w3resource's quiz
Python: Tips of the Day
Find current directory and file's directory:
To get the full path to the directory a Python file is contained in, write this in that file:
import os dir_path = os.path.dirname(os.path.realpath(__file__))
(Note that the incantation above won't work if you've already used os.chdir() to change your current working directory, since the value of the __file__ constant is relative to the current working directory and is not changed by an os.chdir() call.)
To get the current working directory use
import os cwd = os.getcwd()
Documentation references for the modules, constants and functions used above:
- The os and os.path modules.
- The __file__ constant
- os.path.realpath(path) (returns "the canonical path of the specified filename, eliminating any symbolic links encountered in the path")
- os.path.dirname(path) (returns "the directory name of pathname path")
- os.getcwd() (returns "a string representing the current working directory")
- os.chdir(path) ("change the current working directory to path")
Ref: https://bit.ly/3fy0R6m
- New Content published on w3resource:
- HTML-CSS Practical: Exercises, Practice, Solution
- Java Regular Expression: Exercises, Practice, Solution
- Scala Programming Exercises, Practice, Solution
- Python Itertools exercises
- Python Numpy exercises
- Python GeoPy Package exercises
- Python Pandas exercises
- Python nltk exercises
- Python BeautifulSoup exercises
- Form Template
- Composer - PHP Package Manager
- PHPUnit - PHP Testing
- Laravel - PHP Framework
- Angular - JavaScript Framework
- Vue - JavaScript Framework
- Jest - JavaScript Testing Framework